어쩌다보니 다른 미션들의 내용이 섞였다. 저는 payment에서 타입스크립트를 쓰지 않았습니닷
여기 학습로그 추천 :
https://github.com/woowacourse/react-payments/pull/24
https://yung-developer.tistory.com/92
Presentationer / Conainter 컴포넌트를 나누어야할까?

https://blueshw.github.io/2017/06/26/presentaional-component-container-component/
https://rinae.dev/posts/ui-as-an-afterthought-kr
정의
presentational 컴포넌트
: 어떻게 보여지는지와 관련된 컴포넌트
: 상태를 거의 가지고 있지 않다. (상태를 가지고 있어도 UI상태에 관한 것일 것이다.)
: prop으로 데이터를 받고, 데이터를 가져오거나 변경하는 방법에 대해서 관여할 필요가 없다.
: redux,flux같은 store들에 의존적이지 않다.
container 컴포넌트
: 어떻게 동작하는지와 관련있다.
: 스타일 및 DOM 마크업을 거의 가지고 있지 않다.
: 데이터와 행동(기능)을 presentational 컴포넌트에 제공한다.
: flux, redux 액션을 호출하는 등의 의존성이 있다.
: 데이터 소스 역할을 하기 때문에 상태가 자주 변경된다.
장점
: 앱의 기능과 UI에 대한 구분을 이해하기가 더 수월하다. 관심사의 분리
: 재사용성이 뛰어나다. 완전히 서로 다른 상태값과 함께 presentational 컴포넌트를 사용할 수 있기 때문이다.
(this.props.children을 통해서 다른곳에서 사용되어질 수 있음)
: presentational 컴포넌트만 따로 떼어서, 앱의 실제 로직을 건들지 않고 디자인에 대한 테스트가 가능하다.
(뇌피셜)
나는 나누는것이 좋다고 생각한다.
데이터를 쏴주는 컴포넌트와 데이터를 그리는 컴포넌트가 분리되어있으니 관심사가 분리되어있어서,
디자인 관련 수정이 필요할때에는 presentational 컴포넌트를
데이터 처리 로직관련 수정이 필요할때에는 container 컴포넌트를 바라보기만 하면 되므로 개인적으로 상당히 코드를 작성/수정하는 것에서 편리함을 느꼈다.
그리고 react는 user interface를 만들기 위한 javascript 라이브러리이다.
시작부터 react는 view와 관련된 용도가 짙은 라이브러리였다.
또한, react의 철학중 하나인 component로 UI와 관련이 깊다.
과연 그 UI 컴포넌트가 사용자와의 인터렉션 및 상태를 알게되는 것이 맞을까? 라는 생각이 들었다.
redux도 react에서 상태관리와 관련된 관심사를 분리하고 react에서는 최대한 "상태를 반영한 그리기 동작"만을 하기 위한 역할을 수행하고 있게 도와주고 있지 않은가? (https://youtu.be/L1dtkLeIz-M?t=565)
그래서 상태/데이터 조작과 관련된 부분과, 상태를 반영한 그리기 동작을 구분하여 관리하는 것이
유지보수, 리팩터링에 유리하고 가독성도 높다는 내 나름대로의 결론을 내렸다.
(물론, 너무 간단한 라이브러리라서 container/presentional을 나누면 오히려 복잡해지고 단순히 파일분리 역할만 되는 컴포넌트도 있다고 생각한다. 그런 경우엔 다른 이유가 있다면 합쳐서 관리하는 것도 좋다고 생각한다.)
aria-label의 정확한 역할은 무엇인가?
https://abcdqbbq.tistory.com/77
aria 자체가 html요소에 접근가능한 설명용 텍스트를 넣을 수 있는 역할을 한다. (그래서 스크린 리더가 정보를 읽을 수 있게 됨)
aria-label은 화면에 현재 요소를 설명할 텍스트가 없을 경우에 사용하는 설명용 텍스트를 담고 있다.
aria-labelledby는 화면에 현재 요소를 설명할 텍스트가 있을 경우에 해당 텍스트 영역과 현재 요소를 연결할때 사용한다.
상세 정리
1. aria-label
: 모든 html태그에서 사용가능
: 이미지를 사용해서 시각적 표현을 할 경우에 대체 텍스트 역할을 하기도 함
ex) 햄버거 메뉴 버튼이 있다고 하면 (햄버거 버튼은 이미지로 표현됨)
<button class="bt_menu" aria-label="navigation menu"></button>
으로 사용할 수 있다.
2. aria-labelledby
: 모든 html 태그에서 사용가능
: aria-labelledby는 숨겨져 있는 요소도 참조할 수 있다. (display: none이나 visibility:hidden도 가능~)
: aria-labelledby와 aria-label, 네이티브 텍스트가 함께 사용된다면 aria-labelledby 내용이 최우선된다.
컴포넌트는 어디까지 멍청해져야 하며, 상태는 어디까지 끌어올려져야 하는가?
상태를 끌어올려야하는 이유는 다음과 같다. (https://zereight.tistory.com/957)
요약하자면, 상태를 끌어올리는 것은 source of truth를 만족시키기 위함이다.
react는 단방향 데이터 흐름을 가지기 때문에, 데이터 상태에 대한 단 하나의 원천을 가짐으로서 일관성있는 데이터를 보장할 수 있기 때문이다.
(뇌피셜)
그럼 상태는 어디까지 끌어올려야 하겠는가?
source of truth를 만족할 수 있는 선까지 끌어올리면 된다.
물론 모든 값들을 최상단에 몬다는 상상을 할 수 있겠지만, 오히려 아래 컴포넌트에서 가지고 있는 것보다 더 복잡해질 수 있을 것이다.
그래서 source of truth를 만족하는 최하단까지 끌어올리면 될 것같다. 그 이상 끌어올리면 오히려 독이 될 수도 있다는 생각이다.
그럼 source of truth를 만족하는지는 어떻게 알 수 있을까?
구체적인 방법은 사실 나도 잘 모르겠고, 분명 냄새가 날것이다.
데이터의 출처가 분명하지 않다거나, 마치 변경가능한 전역변수가 코드베이스에 존재하는 것처럼의 악취가 날 것이다.
그 것으로 source of truth를 만족하는지 판단해야 할것같다.
컴포넌트가 어디까지 멍청해야하는지에 대해서도 같은 맥락일 것 같다.
source of truth를 만족하는 선까지 상태를 끌어올려버려서 멍청하게 유지한다면, 재사용성 및 source of truth를 만족할 수 있는 컴포넌트가 될 것 같다.
컴포넌트에서 rest parameter를 사용은 괜찮은 것인가?
해당 parameter로 들어올 수 있는 타입이 예상가능하다면 사용해도 괜찮을 것 같다.
예를들어서

위와 같은 코드는 ...rest로 어떤 종류의 타입이 들어올 수 있을지 예상이 가능하므로 안전하다고 할 수 있다.
만약 타입 추론이 안되는 어떤 값이 들어온다고 생각하면 사용이 꺼려질 것 같다. 내가 모르는 값이 패싱할 수 있기 때문에 내가 해당 컴포넌트를 완벽히 제어할 수 없는 상태라고 생각하기 때문이다.
아래 코드에서 무엇이 더 재사용가능한 컴포넌트인가?


위 방법같은 경우는 사용자가 모든 UI가 완성된 툴팁을 사용하는 것이고,
아래 방법같은 경우는 내부에 다른 컴포넌트를 채울 수 있도록 좀 더 유연함을 제공하고자할 때 사용되는 방법이라고 한다.
아래 방법처럼 구현하게 되면 Tooltip을 구현하는쪽의 난이도 확 올라가고,
Tooltip의 children에 어떤 컴포넌트든 올 수 있으므로 완성된 Tooltip의 UI가 깨지지 않도록 보장을 해야한다.
또한 Tooptip의 구현이 사용하는 쪽에서 계속 반복될 것이므로 비효율적이라고 한다.
(뇌피셜)
그래서 이미 완성된 UI를 제공하고자 하는 (다른 컴포넌트가 들어올 수 없는) 구조이면 위 방법처럼 제공하는 것이 맞고,
어떤 컴포넌트가 들어와야 하는 상황이면 아래처럼 children으로 작성하는 것이 좋을 것 같다.
Styled 컴포넌트와 일반 react 컴포넌트를 구별할 필요가 있는가?

그러니까 위 코드처럼, Styled-component는 특정 prefix를 붙여주고,
react component는 일반적인 태그를 사용함으로써 컴포넌트를 구별하는 방법이 옳으냐 이말이다.

자프는 styled 컴포넌트도 따로 파일을 분리하지 않고 react 컴포넌트와 같은 파일에 몰아넣는다고 한다.
그러면 같은 파일안에 있으므로 굳이 Styled prefix를 붙이지 않아도 충분하기 떄문이다.
(뇌피셜)
근데 나는 styled 컴포넌트를 ~.styled.js/ts 의 파일로 분리하는게 좋다고 생각한다.
이것도 css-in-js 코드들을 하나의 파일에 격리함으로써 같은 주제의 수정 요소들을 한 곳에 몰아넣는 역할을 해서 개인적으로 많은 이점을 보았기 때문이다. 아무튼 개취인것 같다.
또한, style 파일을 분리했다고 react component 파일에 Styled prefix를 붙여주지도 않을 것같다.
styled prefix붙임으로써 styled와 react 컴포넌트를 네이밍을 통해서 분리할 수 있다고 치자.
그게 내가 프로그래밍하는데 있어서 어떤 이점을 가져다 주는지 모르곘다. 오히려 중복 prefix가 늘어나서 가독성이 떨어진다고 생각한다.
아무튼 개취이다
sass랑 scss 차이를 아시나요? 같은 말인가요??
https://velog.io/@jch9537/CSS-SCSS-SASS
sass는 synactiacally awesome style sheet (문법적으로 짱 멋진 스타일 시트)의 줄임말
scss는 sassy css (멋진 css)의 줄임말

위와 같은 문법적인 차이점도 있다.
둘다 css 작업을 쉽게 해주며 가독성과 재사용성을 높여준다는 장점이 있다.
하지만 sass보다 scss가 비교적 최신에 나왔고, scss 가 넓은 범용성과 css의 호환성 등의 장점으로 강세를 보이고 있다고 한다.

useMemo, React.Memo, useCallback 등의 최적화에 대해서 어떻
게 생각하는가
https://rinae.dev/posts/review-when-to-usememo-and-usecallback
더 많은 함수 호출과 더 많은 코드는 결국 더 많은 비용을 초래한다.
실행되는 모든 코드는 비용이고, 메모이제이션 과정을 통해서 비용이 추가된다. 즉, 최적화를 위한 비용이 최적화를 통해 얻을 수 있는 효과보다 크게 될 수도 있다는 뜻이다.
"이 코드가 퍼포먼스에 문제를 일으킬 수 있다"고 성급하게 최적화를 하는 습관은 버리는게 좋고,
합당한 측정근거와 이유가 있으면 그 때해도 늦지 않다.

컴포넌트를 분리하는 기준이 어떻게 되는가
https://ui.toast.com/weekly-pick/ko_20200213
https://overreacted.io/ko/the-elements-of-ui-engineering/
https://overreacted.io/ko/writing-resilient-components/
아토믹 디자인을 사용하는 것을 선호합니다.
장점
1. 어플리케이션과 분리하여 컴포넌트를 개발하고 테스트할 수 있으며, 스타일 가이드 같은 도구에서 볼 수 있다.
2. 또한, 패턴이 확립되면 설계 변경이 필요한 경우에 빠르고 유연성 있는 프로세스를 가질 수 있다.
3. 기존의 컴포넌트들을 재사용하고 있기 때문에 디자인을 일관성 있게 통일할 수 있다.
4. 특정 컴포넌트에 CSS가 강하게 결합되어 있어서 CSS코드를 관리하기 쉽다.
스토리 북을 사용했을때 장점과 단점이 있었다면 설명해주세요.
(뇌피셜)
장점
실시간으로 독립적인 컴포넌트 시각적인 회귀 테스트가 가능하다.
단점
1. 에러의 원인이 표시안되는 경우가 있어서 가끔 디버깅에 어려움이 있다.
2. 자잘한 버그가 존재한다.
useEffect의 역할과 하는 일이 무엇일까요?
https://overreacted.io/ko/a-complete-guide-to-useeffect/
https://zereight.tistory.com/961
useEffect는 단어 그대로 function component에서 side effect를 실행하는 것이다.
react에서 사이드 이펙트란 무엇인가요?
https://www.daleseo.com/react-hooks-use-effect/
컴퓨터공학에서 side effect란
함수의 로컬 상태를 함수 외부에서 변경하는 경우, side effect가 발생했다고함 (순수함수, 부수효과 주제로 검색해봐도 좋을듯)
즉, react에 적용하면, function component 외부에서 로컬 상태의 값이 변경하는 것이 side effect라고 할 수 있겠고,
흔한 경우로 비동기처리가 있다.
그래서 정리하자면,
react에서 side effect란
보통 리액트 컴포넌트가 화면에 렌더링된 이후에 비동기등으로 처리되어야 하는 부수적인 효과들을 side effect라고 일컫는다.
훅에서 꼭 지켜야할 규칙이 있는데 그것들은 무엇이고 그 이유는 무엇일까요?
https://ko.reactjs.org/docs/hooks-rules.html
https://overreacted.io/ko/why-isnt-x-a-hook/
👉 최상위에서만 Hook을 호출해야 한다.
훅은 반복문, 조건문 혹은 중첩된 함수내에서 호출해서는 안되고 ealry return 이 실행되기 전에 호출되어야 한다.
이렇게 해야 컴포넌트가 렌더링 될때마다 항상 동일한 순서로 Hook이 호출되는 것이 보장되고, useState나 useEffect가 여러번 호출되어도 Hook의 상태를 올바르게 유지할 수 있도록 해준다.
왜요?
https://ko.reactjs.org/docs/hooks-rules.html#explanation
에서 설명되어 있듯이,
React는 특정 state가 어떤 useState 호출에 해당하는지 알기 위해서, Hook의 호출 순서를 기억해둔다.
모든 렌더링에서 Hook의 호출 순서는 같기 때문에 해당 state가 어떤 useState로부터 생겨났는지 알 수 있는 것이다.
하지만 조건문안에 선언된다면?
조건문이 false일 경우, 해당 Hook이 호출되지 않아서 호출 순서가 꼬이게 된다..!
그럼 각 상태를 다른 useState와 맵핑할것이고 그냥 터진다.
반복문도 마찬가지이다.
몇번 loop가 돌아갈지 보장할 수 없기 때문에 Hook 호출 순서가 달라질 위험을 잠재적으로 가지고 있게 된다.
👉 오직 React 함수 내에서 Hook을 호출해야 한다.
Hook은 일반적인 자바스크립트 함수에서 호출되면 안되고, react 함수 컴포넌트나 custom Hook에서 호출되어야 한다.
왜요?
https://awesomezero.com/development/reacthook/
useState 같은 훅의 동작원리를 대략적으로 설명해 놓은 블로그이다.
캡쳐한 사진을 살펴보자

위에서 말했듯이 React는 Hook의 호출 순서를 기억한다.
그리고 useState는 context라는 React의 문맥에서 Hook을 array로 받아서 id값을 통해
자기가 관리해야할 state를 할당받고 있다.
그리고 setState함수는 그 상태를 업데이트하는 로직을 가지고 있고,
컴포넌트를 render하는 함수를 가진다.
그리고 그 render함수는 인자로 context에서 어떤 컴포넌트를 렌더링해야하는지 전달 받고 있다.
즉, Hook은 React의 context를 사용할 수 있는 위치에서 호출되어야 한다는 뜻이다.
둘을 합쳐서 말하면
"Hook은 반드시 컴포넌트의 최상위에 선언되어야 한다"
라고 할 수 있겠다.
class 컴포넌트에서 Hook을 호출할 수 있나요?
https://ko.reactjs.org/docs/hooks-faq.html#should-i-use-hooks-classes-or-a-mix-of-both

아니용.
제어 컴포넌트와 비제어 컴포넌트의 차이점은 무엇인가요?
https://yung-developer.tistory.com/92
https://berkbach.com/react-docs-%EB%B2%88%EC%97%AD-forms-35d231f6dd3c
제어 컴포넌트
- React에 값이 완전히 제어되는 컴포넌트
- State를 값으로 넘기고 그 State를 다룰 수 있는 핸들러를 콜백으로 넘긴다.
- 값이 항상 React state와 일치하게 되므로, source of truth를 만족하게 됨.
- 실시간으로 값의 유효성을 검증할 수 있다.
- 실시간으로 값의 형식을 포매팅할 수 있다.
비제어 컴포넌트
- 전통적인 HTML처럼 DOM에 제어되는 컴포넌트
- 오직 사용자만 값과 상호작용을 한다.
- ref를 사용하여 직접 DOM의 값을 가져온다.
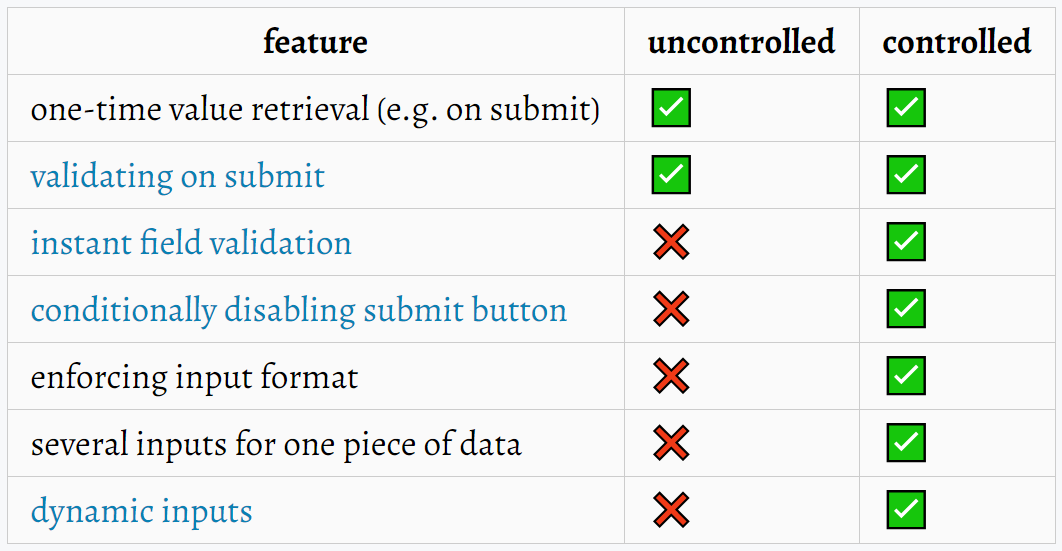
제어 컴포넌트를 지향해야하는 이유는 무엇인가요?


자프님: 비제어 컴포넌트는 데이터를 어플리케이션이 아닌 DOM 자체에서 관여하기에 코드가 필연적으로 지저분해지고 관리하기가 쉽지 않다.
발리스타님(비제어 컴포넌트를 직접 언급하신건 아님): ref에서 current를 접근해서 직접 수정을 하는 것은, react에서 제공하는 life cycle 및 virtual dom 렌더링 depth가 꼬일 위험이 굉장히 높다.
또한 ref를 여기저기서 호출하게 되면, 어디서 로직이 수정되는지 추적이 어려워지며, side effect가 존재합니다. (current가 undefined이거나..)
대부분의 경우 react life cycle을 통해서 해결되는 부분이어서(상태 끌어올리기 등) react 권장 방법을 따르는 것이 좋습니다.
요약하자면
1. DOM 자체에서 관여하기에 코드가 필연적으로 지저분해지고 관리하기가 쉽지 않다.
2. life cycle 및 virtual dom 렌더링 depth가 꼬일 위험이 굉장히 높다.
3. ref를 사용하면 side effect가 존재
4. 대부분의 경우 제어 컴포넌트로도 해결가능하므로 되도록이면 제어 컴포넌트를 사용하면됨.
Form을 어떻게 작성하는 것이 좋은가? 비제어? 제어?
(뇌피셜)
실시간으로 값의 포맷팅, 유효성이 검증되어야하는 경우에 제어컴포넌트를 활용하고,
포커스나 파일 업로드 등의 작업이 필요한 시점에서는 ref를 활용하는 것이 좋다고 생각된다.
즉, 혼용하면 될것 같다 >_<
비제어 컴포넌트는 언제 사용해야 하나요?
ref를 언제 사용해야하나요? 랑 같은 질문이라고 생각
https://zereight.tistory.com/957
전역 변수 사용은 지양되어야 합니다. 근데 React에서는 전역 상태를 사용하는데요. 그래도 되는 걸까요?
전역 변수를 사용하면 안되는 이유는 코드 베이스 상에서 언제 어디서 해당 변수를 변경할지 예측할 수 없기 떄문이다.
하지만 React에서의 전역 상태는 React에서 컨트롤하는 등의 캡슐화가 되어있기 때문에 상관없다고 생각한다.
dependencies array는 항상 채워져야 할까요?

https://overreacted.io/ko/a-complete-guide-to-useeffect/
위 글에 나와있듯이, 의존성 배열을 지워서 useEffect를 속이는 것은 권장되지 않는다.
useEffect를 속여야하는 상황이 온다면 그것은 설게가 잘못된것이라고 보면 되는 것 같다.
속여서 warning이 노출되는 상태로도 동작이 잘되게 할 수 있지만, 그에 따른 부작용이 예기치 못하게 발생할 수 있다.
물론 지금까지 많이 속여왔지만, 최대한 의존성배열은 속이지 말아야 겠다.
지금 질문은 Dan이랑 자프의 의견이 충돌하는 모습이다.
재사용 가능한 컴포넌트란 무엇일까요?
(뇌피셜)
독립적으로 다른 위치, 다른 맥락에서 사용할 수 있는 컴포넌트가 재사용한 컴포넌트라고 생각한다.
커스텀훅은 언제 추출해야할까요?
(뇌피셜)
코드의 중복이 보일 때, 관심사를 한곳으로 모으고 싶을때 추출하면 될 것 같다.
useEffect를 남발해서는 안되는 이유는 무엇인가요?
(뇌피셜)
useEffect를 남용하게 되면,
1. 가독성이 떨어지고 뭔가 잘못 작성되어지고 있다는 느낌을 받게된다.
2. useEffect는 DOM 렌더링이 끝나고 수행되는 동작이기 때문에, DOM 렌더링이 끝나고 react 컴포넌트에서 추가작업이 많다는 것은 동작하고 있는 데이터 흐름을 예측하기 어렵게 해준다. (side effect를 많이 만들어내는 것이기 때문이다.)
render prop이라는 용어를 아시나요?
https://ko.reactjs.org/docs/render-props.html
redner prop 이란, React 컴포넌트 간에 코드를 공유하기 위해 prop을 이용하는 간단한 테크닉이다.
render prop 패턴으로 구현된 컴포넌트는 자체적으로 렌더링 로직을 구현하는 대신, react 엘리먼트 요소를 반환하고 이를 호출하는 함수를 사용한다.
즉, render prop는 무엇을 렌더링할지 컴포넌트에 인자로 알려주는 함수 패턴인 것입니다.
이러한 개념은 HOC을 만들때에도 동일한 맥락을 가지고 갑니다.
styled 컴포넌트는 react 컴포넌트와 가깝게 위치하여야 하는가
(뇌피셜)
컴포넌트는 하나의 독립적인 존재이므로 그에 사용되는 스타일 및 로직들이 가깝게 위치해야 한다고 생각한다.
프로젝트에서 디렉토리 구조를 어떻게 구성하였는가?
(뇌피셜)
컴포넌트는 크게 아토믹 디자인의 폴더 구조를 따랐으며 (payment 미션에는 적용안했음)
컴포넌트 종류가 있으면 해당 네임의 폴더를 구성하고 내부에,
react 컴포넌트가 있는 메인 파일, styled 컴포넌트가 있는 스타일 파일, test 용 파일들을 모았다.
fetch와 axios의 장단점은?
fetch 특징
1. 라이브러리를 import 하지 않아도 된다.
2. 비동기 기반이다.
3. 네트워크 에러가 발생했을 때, 계속 기다려야 한다.
4. 지원하지 않는 브라우저가 있다. (IE)
axios 특징
1. 사용하기가 fetch보다 편리하다. post body에 stringify안해도 되는등의 JSON 데이터의 자동 변환 수행
2. 비동기 기반이다.
3. fetch에서 제공하지 않는 기능들이 있다.
4. fetch보다는 용량이 크다.
5. 지원하지 않는 브라우저가 있다. (IE)
React에서 a태그 보다 Link 태그를 사용하는 이유는 무엇인가요
왜냐하면, a태그는 페이지를 이동시키면서, 페이지를 아예 새로 불러오므로 SPA가 되지 않는다.
새로 페이지가 렌더링 되면서 state등이 모두 초기화된다...
Link는 HTML5의 history api를 사용해서 브라우저의 주소만 바꾸고 페이지를 새로 불러올 수 있게 해준다.
Route와 Link 태그의 차이점은?
Route는 특정 주소에 따라서 컴포넌트를 연결시키는 역할을 한다.
Link는 컴포넌트를 클릭하면 다른 주소로 이동시키게 한다.
Lazy initial state 에 대해서 아시나요?
https://equal-blog.tistory.com/entry/Lazy-Initial-State
기본적으로 React Hook에서는 React 컴포넌트가 다시 렌더링 될 때마다, useState함수가 호출된다.
그러므로, 초기 데이터를 가져오는 부분이 오래 걸리는 동작이라면, 성능적으로 문제가 발생하게 될 것이다.
이러한 문제를 해결하기 위해서, useState 함수는 인자를 함수로 받는 경웨,
React Component가 생성될 때만 state가 생성되게 해준다.
이것을 lazy initial state라고 부른다.
createRef와 useRef의 차이점은 무엇인가요?

createRef: 클래스 컴포넌트에서 사용됨
useRef: 함수 컴포넌트에서 사용됨.
물론 함수 컴포넌트에서 createRef를 사용할 수 있으나, hook이 아니라서 상태를 가지지 못한다.
즉, 컴포넌트가 새로 호출될때마다 초기화가 된다는 뜻이다.
컴포넌트의 모든 값 초기화 하기 vs 컴포넌트를 unmount했다가 다시 mount 해버리기

(아 적어놨는데 왜 다 날아갔)
react의 탄생 철학을 살펴보면, 기본의 복잡한 데이터 바인딩을 버리고, DOM에서 변경사항이 있을 경우 그 DOM을 버리고 새로 그린다는 철학을 가지고 있다.
만약 특정 element의 초기화를 하는 것에 복잡한 로직과 비용이 소모된다면, 굳이 react의 철학을 어길 필요없이
현재 컴포넌트를 폐기하고(unmount)하고 새로 그리는 것이 더 낫다고 생각한다.
Typescript에서 interface와 type의 차이는 무엇인가요?
https://velog.io/@swimme/Typescript-type-vs-Interface
https://codingmoondoll.tistory.com/entry/Type-vs-Interface
https://stackoverflow.com/questions/37233735/typescript-interfaces-vs-types


https://medium.com/@alexsung/typescript-type과-interface-차이-86666e3e90c

type과 interface는 다양한 문법 차이점이 있으나,
가장 중요한 차이점은
1. interface는 확장에 용이하다는 것이다.
소프트웨어에서 확장성은 좋은 소프트웨어의 기준이 되기에 중요하다.
예를들어서

인터페이스는 위와 같이 같은 name을 선언해도 확장이 가능하다. (여러번 정의가능하다.) (Declaration Merging이라고도 한다.)
하지만 type alias는 저렇게 하면 에러를 발생시킨다.
이게 왜 좋냐면
("This is useful for the ambient type declarations of third party libraries. When some declarations are missing for a third party library, you can declare the interface again with the same name and add new properties and methods.")
서드파티 라이브러리에서의 타입확장이 용이하기 떄문이다.
2. interface는 객체지향의 원리에 알맞다.
interface는 객체 구조와 비슷하게 정의되어서 객체 지향적인 코드에 반영하면 가독성이 놓아지고,
이를 지향하는 프로그래머들이 오랜기간동안 사용해왔다.
3. 즉, type은 위 2가지의 특성을 만족하지는 못한다.
하지만 type은 interface가 표현할 수 없는 형태인 다양한 원시/참조값들에 대해서 정의가 가능하고, union/tuple같은 구조도 만들어낼 수 있다.
그러니까 interface 로 표현할 수 없는 형태이고, union/tuple을 이용해야 한다면, type alias를 이용하자.
하지만 그 외의 경우라면 수십년간 사용되어온 객체지향과 알맞는 interface문법을 사용하지 않을 이유가 없다.
좀 더 자세하게 요약된 이미지를 공유한다.

타입스크립트 interface 선언에서 헝가리안 표기법에 대해서 설명해주세요
https://zereight.tistory.com/948
헝가리안 표기법은 컴퓨터 프로그래밍에서 변수나 함수의 이름에 그 종류(타입)을 명시하는 표기법이다.
예를 들어서,
I는 interface
C는 클래스
A는 추상 클래스
S는 문자열
c는 const 변수
i는 정수형 변수
에 해당하는 의미를 가지고 있다.
이런 표기법은 IDE가 많이 발달하지 않은 시절, 네이밍만으로 해당 변수의 타입을 알 수 있어서 매우 유용하게 사용되었다.
하지만 IDE가 발달하면서 마우스를 hover하는 것만으로도 타입을 추론할 수 있게 되었고,
이제 prefix를 붙이는 것은 다음과 같은 단점을 가지게 되었다.
1. 변수, 함수 인자의 이름을 기억하기 어려워진다.
2. 데이터 타입이 바뀌면 이름도 싹 다 바꿔줘야 한다.
3. prefix가 캡슐화 원칙에 위배된다.
=> 캡슐화 원칙으로 인해 외부에서는 내부에서 사용되어지는 타입을 알 필요가 없어야함.
하지만 사용자는 변수를 읽음으로서 타입에 대한 정보를 얻을 수 있으므로 원칙 위배
4. prefix를 붙이는 것이 변수 네이밍을 대충 짓게함 (진짠가)
5. 가독성이 떨어진다.
6. 옛날에 헝가리안 표기법을 권장했던 마이크로소프트도 이제 헝가리안 표기법을 버렸다.
=> 하지만 C#에서는 아키텍처적인 이유로 헝가리안 표기법 사용중
7. 일관성을 파괴하는 네이밍 컨벤션
=> 하나의 프로젝트에서 어떤건 헝가리안 표기법을 사용하고 어떤건 camel case를 사용하고 어떤건 snake case를 사용한다면 일관성도 없고 가독성도 떨어질 것이다.
8. 컨벤션의 목적과 언어(여기서는 js/ts)가 근본적으로 맞지 않다.
=> 변수/함수에 타입을 드러내기 위해서 사용하던 헝가리식 표기법을 구조적 타이핑을 기반으로 하는 ts에 적용하는 것은 말이 되지 않는다. (구조적 타이핑인데 왜 명목적 타이핑처럼 보이게 하려고 하냐는 뜻)
구조적 타이핑 vs 명목적 타이핑 (https://typescript-kr.github.io/pages/type-compatibility.html)
나머지 단점 https://en.wikipedia.org/wiki/Hungarian_notation#Advantages
왜 React Component의 타입으로 React.FC나 React.VFC같은 타입을 명시해주지 않았나요?
https://react-typescript-cheatsheet.netlify.app/docs/basic/getting-started/function_components
https://fettblog.eu/typescript-react-why-i-dont-use-react-fc/
안쓴다는 입장 https://darrengwon.tistory.com/768
1. VFC, FC 타입을 사용하지 않는 것이 좋습니다. - jbee
VoidFunctionComponent라는 타입은 임시적으로 react에서 제공하고 있는 타입이라서 사용하지 않는 것이 좋다. (@types/react 18 버전에서 deprecated될 버전이다.)
2. 쓰지마라 - 벨로퍼트
https://react.vlpt.us/using-typescript/02-ts-react-basic.html
하지만 장점도 있다. (컴포넌트의 타입이 undefined 등의 이상한 값일 때를 체크할 수 있는 등.)
https://github.com/facebook/create-react-app/pull/8177
디렉토리구조에 있어서 index.js를 re-export하는 것에 대해서 어떻게 생각하시나요?

동의한다.
import 구문의 코드를 많이 줄일 수 있고, index파일에서 다른 파일들을 모아놓기 때문에 필요한 출구가 1개인 효과(?)가 있어서 출처를 밝히기도 쉬워질 것 같다.
하지만 단점으로는 프로젝트가 커질 수록, index라는 이름의 파일이 매우 많아진다는것이다.
코드도 아니고, 파일의 이름 중복이 많아지는 것이 나쁜것인가? 라는 생각이 들었다.
px, rem, em의 차이를 아시나요? 뭘 쓰는게 좋을까요
https://medium.com/watcha/watcha-개발-지식-px-em-rem-f569c6e76e66
px
어떤 화면의 물리적인 좌표 혹은 지점
모니터의 픽셀과 브라우저의 픽셀은 다르게 계산되고 여기서의 px은 브라우저 px이다.
em
em은 적용된 엘리먼트의 글자 크기에 비례한다.
퍼블리싱을 하다보면 디자인의 변경 요구사항 등 여러가지 이유로 글자 크기나 기타 요소들이 바뀔 상황이 비일비재한데,
em의 가장 큰 단점은, 하필 자기 자신의 글자 크기를 참조하기 때문에 em을 사용하는 다른 속성 역시 글자 크기에 영향을 받을 수 밖에 없다. 그래서 내가 변경되지 않더라도, 부모의 글자 크기가 변경되면 자식들의 폰트 크기가 싹다 바뀌어버릴 수 있다.
rem
rem역시 em과 마찬가지로, 글자 크기에 따라 비례되는 속성이다.
em과의 차이점은 rem은 html 태그의 글자 크기만 참조한다.
솔직히 어떤 단위가 제일 좋다고 특정하기는 어렵다.
https://www.youtube.com/watch?v=xWMKz9NCD0k
위 엘리님의 동영상의 내용을 참고하여 정리하자면,
부모 vs 브라우저
- 부모요소에 대해서 반응해야 되는경우에는 %, em을 사용한다.
- browser에 대해 반응해야 되는경우에는 v*, rem을 사용한다.
box vs font-size
- 요소의 너비와 높이 (box-model)에 반응해야 하는 경우: %, ㅍ*
- font-size에 따라 반응해야 하는 경우: em, rem
로 사용하면 된다고 한다.
발리스타가 항상 0px에서 px를 떼라고 하시는 이유가 뭘까요?
https://zereight.tistory.com/892
웹팩이 번들링할때 px를 떼는 작업이 이루어지는데, 그것이 결국 비용이기 때문이다.
px가 100만개 있다면, px를 안적어줄시에 200만개의 문자를 최적화하는 것과 같은 효과를 줄 수 있기 때문이라고 한다.
타입스크립트에서 "Partial"과 "elem?: T"의 차이는 뭘까요?

Parital은 타입변수의 프로퍼티들이 모두 optional로 바꾸는 것이고,
elem?: T 은 인자 자체를 전달할 것이냐의 optional 여부를 뜻한다.
즉, Parital은 인자 자체가 optional이 아니기 때문에 빈 객체라도 전달해주어야 하고, (대신에 내부 프로퍼티는 optional)
elem?: T는 인자 자체가 optional이기 때문에 빈 객체를 전달해주어도 됩니다.
리액트에서 prop와 state란 무엇인가요?
https://velog.io/@kyusung/리액트-교과서-React-컴포넌트와-상태-객체
react에는 컴포넌트간에 단방향으로 데이터를 주고 받는 props와
컴포넌트 내부에서 사용하는 state가 있다.
- props
props는 부모 컴포넌트에서 자식 컴포넌트로 데이터를 전달할 때 사용되며 변경이 불가능 하다.
- state
컴포넌트에서 관리하는 상태 값으로 유동적인 데이터를 다룰 때, state를 사용한다.
state는 변경이 가능한데 직접적으로 변경을 할 수 없고, setState등의 함수를 통하여 변경할 수 있다.
(한 번의 렌더링에서 state는 고정이라는 것도 알아두자)
값, 식, 문에 대해서 설명해주세요.
값은 프로그램에 의해 조작될 수 있는 대상을 뜻한다.
값은 다양한 방법을 생성할 수 있으며, 가장 간단한 표기법은 리터럴이다.
식은 하나의 값으로 평가된다.
값, 변수, 객체의 프로퍼티, 함수 호출, 연산자 조합 등은 몯 표현식이며 하나의 값으로 평가된다.
문은 리터럴, 연산자, 표현식, 기워드 등으로 구성되며 세미콜론으로 끝난다.
문은 코드 블록으로 그룹화할 수 있으며, 그룹화의 목적은 함께 실행되어야 하는 문을 정의하기 위함이다.
동적 타이핑, 정적 타이핑은 각각 무엇인가요?
정적타입 언어
: 컴파일 시 변수의 타입이 결정되는 언어를 말한다.
: 따라서 프로그래머가 변수에 들어갈 값의 형태에 따라 직접 변수의 타입을 명시해주어야 한다.
: 타입 에러로 인한 문제점을 초기에 발견할 수 있어서 타입의 안정성이 높다.
: 컴파일 시에 미리 타입을 결정하기 때문에 실행속도가 빠르다.
: 매번 코드 작성 시 변수형을 결정해주어야 하는 번거로움이 있다.
동적타입 언어
: 컴파일 시 자료형을 정하는 것이 아니라 런타임 시 결정된다.
: 런타임까지 타입에 대한 결정을 끌고 갈 수 있기 때문에 유연성이 높다.
: 컴파일 시 타입을 명시해주지 않아도 되기 때문에 빠르게 코드를 작성할 수 있다.
: 실행 도중에 변수가 예상치 못한 타입이 들어와서 타입에러가 발생할 수 있다.
=> 동적 타입 언어는 런타임 시 확인할 수 밖에 없기 때문에, 코드가 길고 복잡해질 경우 에러를 찾기가 어려워진다.
'개발 > Web Programming' 카테고리의 다른 글
| 우테코 react-shopping-cart 학습로그 작성 (0) | 2021.06.14 |
|---|---|
| 내가 보려고 만든 "useEffect 완벽 가이드" 요약 (1) | 2021.06.13 |
| styled-component를 작성할때 참고하면 좋은 곳 (0) | 2021.06.12 |
| ts로 슬랙봇 만들면서 느낀점 (3) | 2021.06.12 |
| 우테코 react-lotto 미션 학습로그 (3) | 2021.06.10 |
